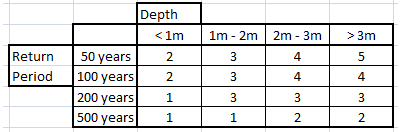
One of the recurrent themes of this blog is to explore the usefulness and limitations of risk models. This post explores the implications of the widespread — in some cases, universal — use of these models. Is there a limit to a model’s usefulness if everyone is using it? How can a model’s limitations be overcome?
When a peril is well modeled, and that model is comprehensively applied throughout a market by both the carriers and re-insurers, it becomes very difficult to differentiate coverage because everyone has priced the risk similarly. The implications of this blanket usage begin to manifest when nothing happens for a while; i.e., when no significant catastrophe fulfills the model’s predictions. The capacity to cover the expected loss is collected by everyone, and with no claims to release the capital, the market gets soft. Competition becomes tighter, and it becomes necessary to look for new markets, or entirely new activities, to maintain a constant level of premium.
This recent article from Intelligent Insurer explores this phenomenon in the current reinsurance market. The big boys are moving to specialty reinsurance and even primary insurance amid a very soft market. Naïve capital accumulates and the only outlet is a catastrophe that is unexpected — i.e., unmodeled – to release the excess capacity through claims that exceed predictions.