
Many solution providers in the market today use addresses as input to determine the risk from multiple perils at a specific location.

Many solution providers in the market today use addresses as input to determine the risk from multiple perils at a specific location.
Topics: InsitePro, Risk Management, Risk Scoring

One of the recurrent themes of this blog is to explore the usefulness and limitations of risk models. This post explores the implications of the widespread — in some cases, universal — use of these models. Is there a limit to a model’s usefulness if everyone is using it? How can a model’s limitations be overcome?
When a peril is well modeled, and that model is comprehensively applied throughout a market by both the carriers and re-insurers, it becomes very difficult to differentiate coverage because everyone has priced the risk similarly. The implications of this blanket usage begin to manifest when nothing happens for a while; i.e., when no significant catastrophe fulfills the model’s predictions. The capacity to cover the expected loss is collected by everyone, and with no claims to release the capital, the market gets soft. Competition becomes tighter, and it becomes necessary to look for new markets, or entirely new activities, to maintain a constant level of premium.
This recent article from Intelligent Insurer explores this phenomenon in the current reinsurance market. The big boys are moving to specialty reinsurance and even primary insurance amid a very soft market. Naïve capital accumulates and the only outlet is a catastrophe that is unexpected — i.e., unmodeled – to release the excess capacity through claims that exceed predictions.
Topics: Insurance Underwriting, Risk Management, Other Risk Models
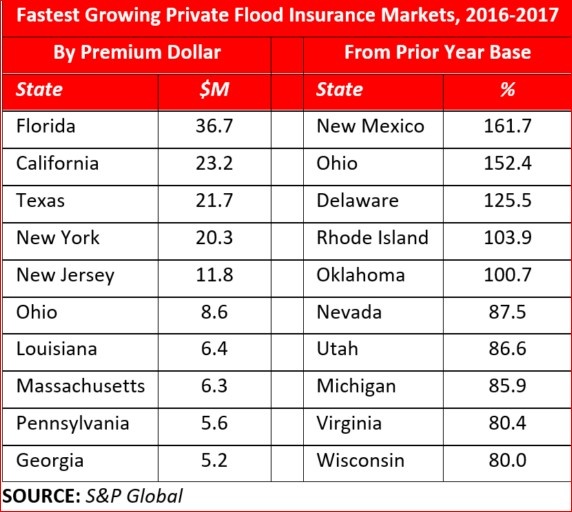
A tumultuous U.S. Nat Cat 2017 year bookended by huge first quarter losses from hail and tornado and an estimated $50bn+ insured losses from HIM (Harvey, Irma, and Maria) still did not impede the private flood insurance market from growing by 51.2% according to information referenced in an Insurance Journal article published on March 18th of this year. That news comes despite Congress’ delay in reform and reauthorization of the NFIP, currently +-$25 billion in debt (pre HIM).
Topics: Floods, Flood Insurance, Flood Risk, Private Flood

PropertyCasualty360 published an article in December, 2017 that begins with this eye-opening quote, “Research conducted by a team of U.S. and U.K. scientists and engineers suggests that U.S. federal flood maps underestimate the number of Americans at risk for flood by more than 27 million people.”
A study from IOPscience gave a more onerous estimate of 41 million Americans living on the 100 year floodplain. And, with a value of $5.5 trillion! In contrast, current FEMA estimates are around 13 million Americans.
At the 2017 American Geophysical Union Meeting Dec. 11-15 in New Orleans, scientists presented a ‘redrawn’ flood map of the U.S. (coastal areas excluded) simulating every river catchment area. Intermap’s InsitePro flood mapping tool uses a mathematical tree structure called the Strahler Number to predict risk. It is a numbering system that correlates a numeric value to stream size from small tributaries to large riverways. The entire algorithm then uses our proprietary 5m seamless & contiguous bare earth elevation dataset to generate location specific flood risk scores.
Topics: Floods, Flood Insurance, Flood Risk, Risk Scoring, FEMA

Modeling how a river will flood, or how the sea will rise over the shore, or how rain will accumulate and flood an area, is a tricky thing to do. The variables are limitless, and of course an act of nature is by definition unpredictable. Algorithms can get more and more complicated as these variables are accounted for in the model, but in the end it’s impossible to model things like trees accumulating under bridges to create ad hoc dams. What can really help a flood model’s quality is the foundation upon which it’s built: the empirical ingredients, like elevation data.
Topics: Floods, Risk Management, Flood Modeling
Welcome to The Risks of Hazard, brought to you by Intermap Technologies®. From the latest industry news and trends, to insight from thought leaders around the globe, stay tuned for a variety of content aimed at helping you better understand the role of location-based intelligence in the world of insurance underwriting and risk assessment.
To see how Intermap delivers analytics tailored to your underwriting, visit our InsitePro page.